Information Asset Security Policies, Frameworks, Standards and Guidelines
Devon Park's morning starts with a compliance dashboard showing 40% of Meridian Corp systems below the password complexity standard. He traces the path upward: the policy exists, a framework is referenced, a guideline recommends best practices. But no one can produce the document that translates the policy's intent into a specific, mandatory minimum character requirement. The security architect shrugs — 'We follow the spirit of it.' The compliance deadline is Friday. Devon opens the governance documentation folder and stares at the gap between the policy shelf and the guidelines shelf.

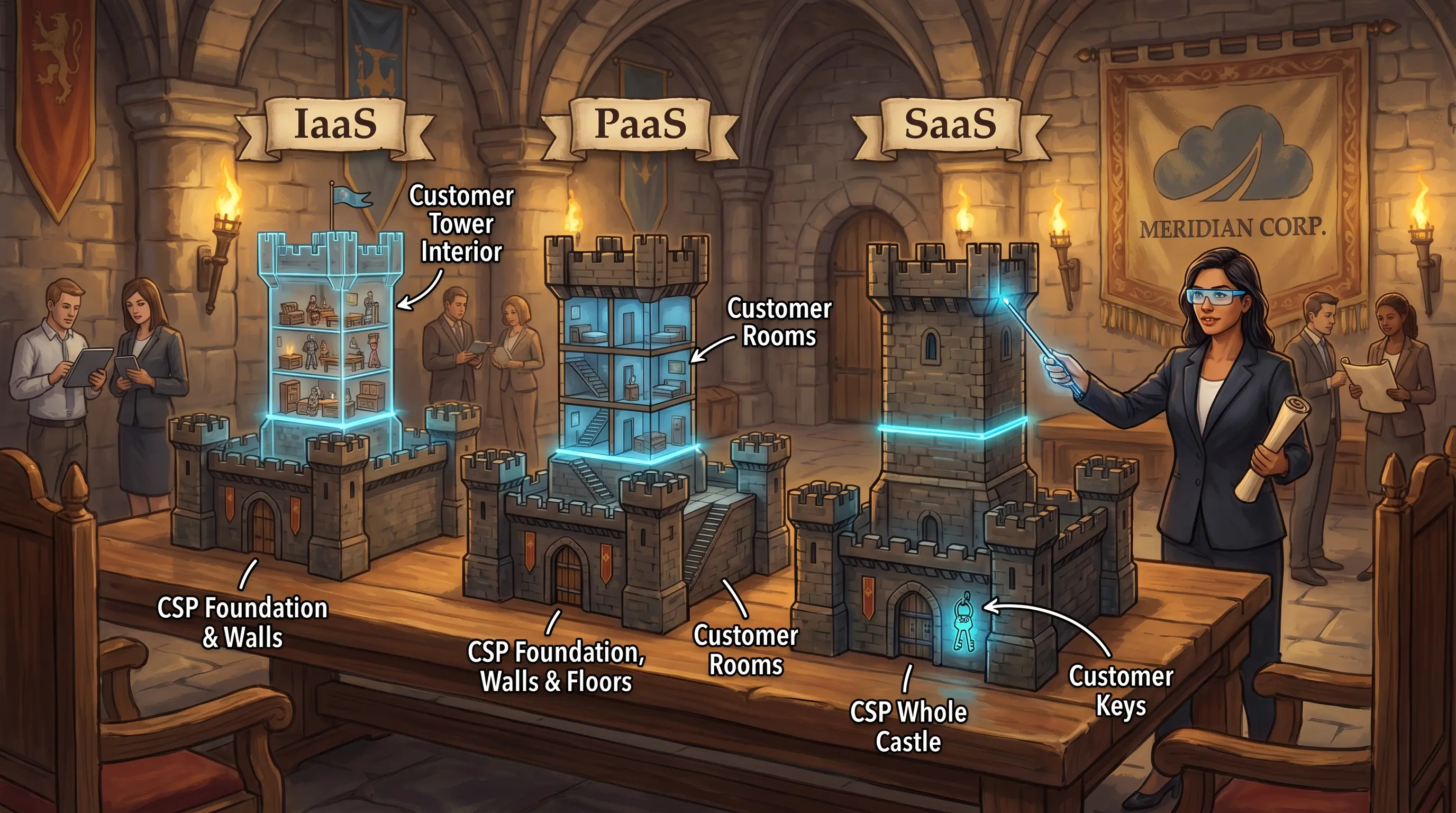
Information security governance uses a layered document hierarchy to translate senior management intent into technical controls. At the top, security policies articulate management's commitment and high-level requirements for protecting information assets. Frameworks, such as ISO 27001 or the NIST Cybersecurity Framework, provide a structured approach for organizing security controls and processes. Standards specify mandatory technical requirements that implement policy—for example, minimum encryption key length or password complexity rules. Guidelines offer advisory, best-practice recommendations for how to implement standards in specific contexts. Each lower layer becomes more specific and technical. The hierarchy ensures that board-level security intent flows down to the individuals and systems responsible for implementing controls. The IS auditor verifies that all layers exist, are consistent with each other, and are actively enforced.
Policies
What do security policies do?
- Express management intent and commitment
- Set high-level security requirements
- Mandatory — must be followed
- Approved and issued by senior management
Frameworks
What role does a security framework play?
- Provides structure for organizing controls
- Examples: ISO 27001, NIST CSF, COBIT
- Connects policy to specific control domains
- Reference for gap analysis and benchmarking
Standards
How do standards differ from policies?
- Mandatory, specific technical requirements
- Derived from policy to make it actionable
- Examples: minimum password length, encryption type
- Non-compliance is a policy violation
Guidelines
When would you use a guideline vs. a standard?
- Guidelines are advisory, not mandatory
- Provide best-practice implementation guidance
- Used where context requires flexibility
- Support standards without replacing them
Meridian Corp's InfoSec team enforces password complexity requirements inconsistently—some systems require 12 characters, others accept 6. Which layer of the security governance hierarchy is the correct place to define and mandate the specific password complexity requirement?
Information security governance operates through a layered hierarchy. Policies express senior management's intent and high-level requirements. Frameworks (such as ISO 27001, NIST CSF, or COBIT) provide the structural blueprint for organizing controls. Standards translate policy intent into specific, mandatory technical requirements—such as minimum password length—that apply across the organization. Guidelines provide advisory best-practice guidance for implementing standards. Inconsistent password requirements indicate a missing or unenforced standard. The IS auditor assesses whether all four layers are present, consistent, and enforced.
On the CISA exam, standards are mandatory; guidelines are advisory. If a question asks what 'must' apply across the organization, the answer is a standard. If a question asks for flexible, context-specific guidance, the answer is a guideline.
Target 2013 breach — the written policy required vendor isolation; the actual network let Fazio Mechanical, an HVAC contractor, reach the point-of-sale systems via credentials stolen through a phishing email. Attackers used pass-the-hash techniques to escalate from the vendor portal to domain admin, deploying BlackPOS malware on POS devices and exfiltrating 40 million payment card records and 70 million PII records. A policy nobody enforces is worse than no policy because it signals false assurance.